ChatDLM Technical Report
Date: April 2025
Author: Qafind Labs
Abstract
ChatDLM is the first model to deeply integrate Block Diffusion with a Mixture-of-Experts (MoE) architecture and achieve industry-leading inference speed on GPU. Leveraging parallel block-level diffusion, dynamic expert routing, and an ultra-large context window, ChatDLM sustains 2,800 tokens/s on NVIDIA A100 GPUs, unlocking new possibilities for document-scale generation and real-time interaction.
1. Model Overview
- Model Type: Block Diffusion-based DLM + MoE
- Parameter Size: 7B
- Context Window: 131,072 tokens
- GPU Inference Speed: 2,800 tokens/s on A100
2. Core Components
2.1 Block Diffusion
- Text Partitioning: Split input into blocks (e.g., 512 tokens/block) and perform diffusion in continuous space in parallel.
- Reverse Denoising: At each iteration, apply the trained denoising network to each block, combined with cross-block attention for global context.
- Iteration Schedule: Default 12–25 steps, dynamically adjusted per-block convergence.
2.2 Block Parallelism
Simultaneously execute reverse denoising on all blocks. Cross-block summary tokens enable context sharing across blocks, reducing complexity approx. from O(n²) to O(n√n) and significantly boosting throughput.
2.3 Mixture-of-Experts (MoE)
- Each layer contains 32–64 experts; a gating network selects Top-2 experts per input.
- Expert routing runs in parallel with diffusion denoising, enhancing expressiveness with minimal overhead.
2.4 Ultra-Large Context Window
- Fine-tuned Rotary Positional Embeddings (RoPE) enable stable extrapolation from training length (4,096) to inference length (131,072) tokens.
- Hierarchical KV-Cache: full KV storage for recent blocks, low-rank summaries for older blocks, controlling memory footprint.
3. GPU Inference Optimizations
- Dynamic Iteration: Group blocks by convergence difficulty; early-exiting for easy blocks reduces average steps to ~12.
- Mixed Precision: BF16 for all matrix and attention operations ensures numerical stability while saving memory.
- Hybrid Parallelism & ZeRO Sharding: Layer-wise and data parallelism with parameter, activation, and KV-Cache sharding for multi-GPU scaling.
4. Performance Benchmark (A100 GPU)
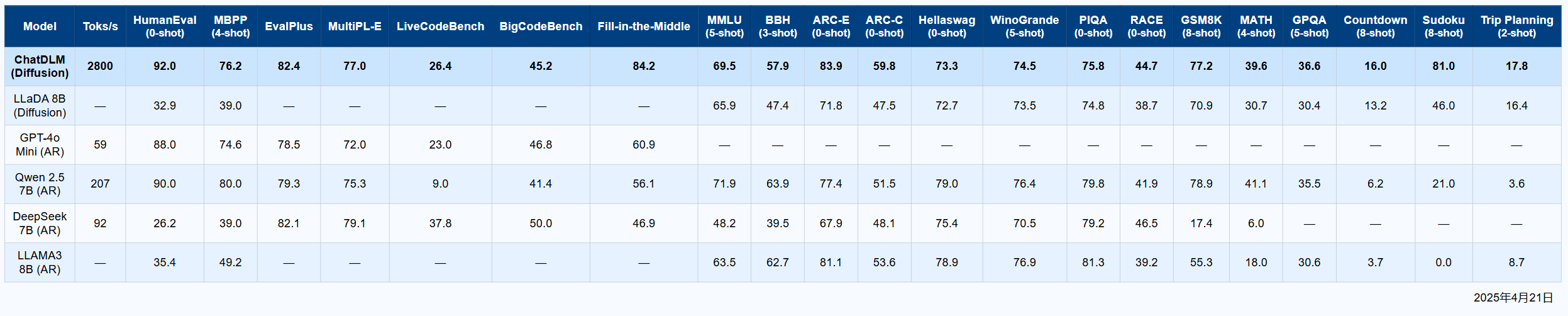
| Metric | Value |
|---|---|
| Tokens/s | 2,800 |
| Context Window | 131,072 tokens |
| Iteration Steps | 12–25 |
| HumanEval (0-shot) | 92.0 |
| Fill-in-the-Middle | 84.2 |
| ARC-E (0-shot) | 83.9 |
5. Conclusion & Future Work
By combining Block Diffusion with dynamic MoE expert routing and optimized GPU inference, ChatDLM achieves an industry-leading 2,800 tokens/s throughput and 131k token context support on A100 GPUs. Future directions include adaptive iteration, graph-attention integration, and multimodal diffusion to meet higher precision and broader scenarios.