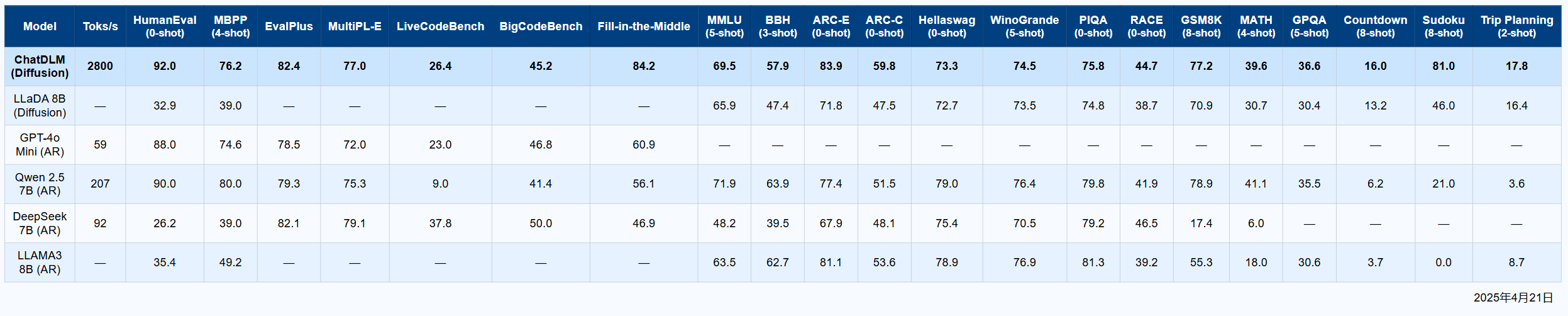
Performance
How ChatDLM compares to other language models
Superior Performance in Key Areas
Data show that ChatDLM offers significant advantages in scenarios such as controllable generation, local inpainting, multi-constraint tasks, numeric countdowns, itinerary planning, Sudoku solving, translation, and more.
Controllable Text Generation
Precision control over generated content
Local Content Editing
Targeted modifications without full regeneration
Complex Problem Solving
Exceptional at structured problems like Sudoku